


Whether it be a highly accurate and precise surgical machine replacing surgeons in operation theaters or a simple face recognition feature replacing your long lengthy and hard to remember passwords, these artificial intelligence-based systems churn through tremendous amounts of data to ensure that they are as close to real outcomes as they could be. The data these models train on, plays a decisive role on how the model would react on unknown and untrained scenarios it is supposed to work on, most people attribute bias to creep in through this data, that we feed into the model, which is what is majorly seen, but is not the only reason of algorithmic bias that exists in AI.
 Image Source: Google Images
Image Source: Google Images
Consider an example of a simple face recognition algorithm at work, it has a simple task of identifying the face of people which could be a preliminary task for a security standard operating procedure, considering this task, it was found out that these models had relatively less accuracy in identifying black faces against their counterpart white faces. Moreover, it was also found that females were found to have even low accuracy compared to males, the worse hit were clearly dark-skinned females, the following comparison shows how some of these models from big tech companies performed on these faces,
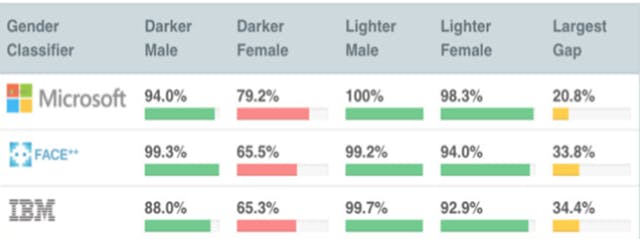
The Center for Data Ethics and Innovation which is the UK government's independent advisory council on data-driven technology, published a research paper titled "A Review on Bias in Algorithmic Decision-Making. ”, this paper found that there was a significant amount of increase in the use of algorithms in key decision-making processes, such as policing, local government, recruitment processes and financial services and found high bias in the algorithms being used. The report called for organizations and independent researchers to actively identify and mitigate algorithmic bias.
To understand why we need to talk more about the algorithmic bias is, because these algorithms that we are now using are at the center of shaping major societal issues at a point of time when machine learning and AI needs to be accepted around the world. If this bias which continues to creep into algorithms which are now forming a key part in the societal decision-making process is not handled, it would have a greater adversarial effect on economically and socially weaker communities which may eventually lead to a clamor which would harm the advancement and global acceptance of an amazingly valuable innovation.
The Decision-Making Process
To understand how this bias affects, It's key to understand how this decision-making process begins with gathering data and concludes with judgements about a person's eligibility for a specific government program.

Image Source: Google Images
1. What do we want to solve?
This is the first step, framing the problem. This determines what we want the outcome of our model to be, this could be anything starting from predicting the growth of a company’s stock price to whether a job applicant should be called for an interview or be rejected even before a human is allowed to review his/her application. For example, a credit card providing company would like to estimate a future customer’s creditworthiness, but the algorithm cannot directly decide whether its primary goal should be to maximize the credit providing company’s profit margins or estimate the amount of people who would go on to repay their loans. Creditworthiness would then be determined based on what the goal of the company is. The problem here is that, in most cases companies prioritize these decisions toward satisfying various business commitments rather than paying attention to the fairness or discrimination. If these algorithms are later found out to be giving a higher creditworthiness score to a certain socioeconomic group like White Americans and are found innate a lower score to a weaker social group like Blacks irrespective of other factors, it would eventually lead to a predatory behavior even if that was not what the company initially intended to do.
2. Collecting Data
As simple as it may sound, this step is where the major amount of bias gets loaded on to the final model. To look at it with a much broader perspective, bias creeps in here through two main ways, firstly due to unrepresentative or under-representation of a certain class of data points while collecting the data. A great example of this could be, a deep learning model with a training data consisting of mostly light-skinned faces, would fail to have even an appreciable score, while working on dark-skinned faces, say on a face recognition task. Another way how bias gets into the data is using historically biased data. This is when the model is trained on historical data such as loan defaulting or crime rate prediction in which the eventual decision making was done in a biased manner,
 Image Source: Google Images
Image Source: Google Images
A great example to understand this is the Amazon hiring model, Amazon planned to build a model on its historical candidate data, for its internal recruiting, for this they used their past candidate data for the purpose of training, on working with it, they found that the model was not rating its candidates for the role of a software developer and additional gender-neutral technical positions. This started to happen because the data used to train the algorithm screened applicants by analyzing for trends in resumes submitted to the firm over a ten-year period. Most of these applicants were men, this led the model into understanding that male candidates were preferable, and it started penalizing resumes which included words like “women” for example, female candidates who mentioned on their resumes “Women’s Football Team Captain” were given a negative score by the model.
3. Preparing the data
This is the final step, before the data is fed into models for them to train on, at this stage, there are already multiple biases from the previous stages, but bias could also be added at this stage, into the model. Primarily at this stage, we select attributes which we want to be fed into our model, attributes which we think are important in deciding the final outcome. In the case of a loan defaulter prediction, attributes could be income, credit score, age of the customer, education level etc., The ability to choose these attributes intelligently is what distinguishes an excellent model, as the decision of which features to consider or ignore can have a substantial impact on the model's prediction accuracy. However, while the influence of attributes on accuracy may be straightforward to quantify, the impact on the model's bias may not.
How are we dealing with this algorithmic bias?
 Image Source: Google Images
Bias is bad, it tilts our model to favor certain classes while predicting, this could mean that there is more influence by specific classes over the decision, which is undesirable at an idealistic state, although currently we are quite far from the ideal case, but there is progress being made in the right direction, certain companies and startups are working on reducing this algorithmic bias in AI, for example a company AI Cure which is a pharmaceutical company whose primary task is to moderate patients on their medications during their clinical trials, the company developed an algorithm to keep a track on its patients through their smartphone to make note of any patient with untaken dose of medicine, and ensures that such patients are noted into the clinical trial data.
The company found that its face recognition algorithm, was not identifying darker-skinned patients, this had happened due to the fact that the dataset used for training the algorithm did not have enough training samples of dark skinned people, after realizing this, the company rebuilt its AI algorithm by adding black faces to its visual systems, due to this the company was able to mitigate its bias issue, currently this algorithm helps the company to keep track of close to a million dosing interactions and works flawlessly with patients of all skin tones.
Image Source: Google Images
Bias is bad, it tilts our model to favor certain classes while predicting, this could mean that there is more influence by specific classes over the decision, which is undesirable at an idealistic state, although currently we are quite far from the ideal case, but there is progress being made in the right direction, certain companies and startups are working on reducing this algorithmic bias in AI, for example a company AI Cure which is a pharmaceutical company whose primary task is to moderate patients on their medications during their clinical trials, the company developed an algorithm to keep a track on its patients through their smartphone to make note of any patient with untaken dose of medicine, and ensures that such patients are noted into the clinical trial data.
The company found that its face recognition algorithm, was not identifying darker-skinned patients, this had happened due to the fact that the dataset used for training the algorithm did not have enough training samples of dark skinned people, after realizing this, the company rebuilt its AI algorithm by adding black faces to its visual systems, due to this the company was able to mitigate its bias issue, currently this algorithm helps the company to keep track of close to a million dosing interactions and works flawlessly with patients of all skin tones.
Researchers across the world are now aiming to use AI research to determine bias in business systems from the outside. Mathematicians like Cathy O’Neil who co-founded a consultancy in the year 2018 which works privately with companies to audit their algorithms and identify and eradicate any bias that their algorithms may have.
 Timnit Gebru
Timnit Gebru
Image Source: BBC
Joy Buolaowini a Ghanaian-US research scientist along with Timinit Gebru, a notable researcher in the field of ethical AI in the year 2018 published a gender shade study the findings of which were shared with all the organizations involved. In 2019, a year later, their follow-up study included a rerun that audited two more companies, Amazon and Kairos. This follow-up study, led by Deborah Raji, a computer scientist at Mozilla Labs, revealed that the two companies had incredibly high accuracy errors, to a stage at which they couldn't classify former American first lady Michelle Obama's images. These studies had a serious influence in the real world, leading to the enactment of two US federal laws, The Algorithmic Accountability Act and the No Bio-metric Barriers Act, both of which were well-established state bills in New York and Massachusetts. This data published by this research also convinced tech behemoths like Microsoft, IBM, and Amazon to put a hold on its policing facial-recognition technology.
Further Readings
Bias in AI is not new, and not something that could be eradicated all at once, to eradicate it, it is important to understand how it happens and how did it become so prominent in the decision making process, below are some links to articles which provide a good analysis of how big-tech companies have been exposed in terms of biased models,
- Wired on: What really happened when Google ousted Timnit Gebru
- Ericsson Research: AI bias and human rights: Why ethical AI matters
- Fortune: A.I.’s role in financial transactions needs the human element of ‘explainability’
- Here is the link of a paper published by Timnit Gebru, which is speculated to be the reason for her being fired from Google Research. On the dangers of stochastic parrots: Can Language Models be too Big?
- MIT Technology Review's take on the paper: We read the paper that forced Timnit Gebru out of Google. Here’s what it says. (Note: May require a paid subscription)
- Harvard Business Review: Ethical Frameworks for AI Aren’t Enough
Conclusion
AI is currently at a crucial stage of being adopted by people around the world, if these algorithms are not robust and have bias inbuilt into them, they would increase the already existing tensions among various socioeconomic groups around the world, this would lead to people losing trust on such systems which could arguably be one of the best scientific and technological advancements of the current century. Bias which could be mitigated if dealt with in a responsible manner and not underestimated is not something which should hamper the large-scale adoption of these algorithms which have been proven to provide a comparatively easier and safer life to people around the globe
Cover image credits: University of Toronto